
Sztuczna inteligencja – terminy, które musisz znać. Część 1. – podstawy

Po “rewolucji AI w 2022 roku” nasuwa się jeden prosty wniosek – sztuczna inteligencja nie jest modą, która wkrótce przeminie, ale pozostanie z nami przez jakiś czas. Zrodziła nowe stanowiska w branży i wiele nowych pojęć. Istnieje szereg terminów związanych ze sztuczną inteligencją. Niektóre z nich są oczywiste, a inne mogą być mylące i niejasne. Mamy nadzieję, że po przeczytaniu naszych artykułów na ten temat nie będziesz zaskoczony, kiedy ktoś rzuci w Twoją stronę terminologią AI.
Podstawowe pojęcia związane ze sztuczną inteligencją
Wyjaśnienie terminów związanych ze sztuczną inteligencją podzieliliśmy na dwie części. W tym artykule omówimy kilka podstawowych pojęć, które pomogą Ci pozostać na bieżąco z tymi zagadnieniami i ugruntować zrozumienie wiedzy związanej z AI. W kolejnym wpisie blogowym skupimy się na bardziej specjalistycznej terminologii i wyjaśnimy wewnętrzne mechanizmy istniejących rozwiązań. Pojęcia w tym blog poście zachowują porządek alfabetyczny zgodnie z angielskim nazewnictwem.
Sztuczna inteligencja (Artificial Intelligence)
Sztuczna inteligencja (AI) to szeroka dziedzina informatyki, skoncentrowana na tworzeniu maszyn zdolnych do wykonywania zadań, które zazwyczaj wymagają ludzkiej inteligencji. Obejmuje to rozwiązywanie problemów, rozpoznawanie wzorców i rozumienie języka naturalnego. Termin ten obejmuje nie tylko sztuczne sieci neuronowe, ale także rozwiązania takie jak algorytmy genetyczne, logikę rozmytą etc.
Model AI/Checkpoint/Wdrożenie modelu (AI Model/Checkpoint/Model Deployment)
Jest to jedna z najbardziej mylących części ogólnego dyskursu.
- Model AI – odnosi się do architektury sztucznej sieci neuronowej. Obejmuje strukturę sieci (warstwy, neurony itd.), wykorzystywane algorytmy i parametry określające zachowanie. Model jest teoretyczną strukturą definiującą jak AI przetwarza dane wejściowe i generuje wyniki.
- Checkpoint – jest to zapisany stan wytrenowanego modelu, w określonym momencie w czasie. Zawiera wszystkie parametry, wagi i tendencje, których model nauczył się do tego momentu. Checkpointy sa używane do pauzowania i wznawiania treningu, odzyskiwania w przypadku zaburzeń pracy oraz do wdrażania wytrenowanego modelu w różnych środowiskach. Reprezentuje instancję modelu wraz z nauczoną wiedzą na pewnym etapie treningu.
- Wdrożenie modelu – gdy masz model, musisz go “wdrożyć”. Obejmuje to tworzenie lub korzystanie z dostępnych aplikacji lub skryptów (więcej na ten temat przeczytasz w kolejnym artykule) w celu zapewnienia interfejsu do interakcji z modelem. Zawiera to również infrastrukturę, taką jak serwer z procesorem graficznym, interfejs sieciowy lub interfejs API dla użytkowników do interakcji z modelem.
Dla utrwalenia – kiedy mówisz “używam ChatGPT”, odnosisz się do całego systemu, który umożliwia interakcję z modelem “ChatGPT”.
Big Data
Ten termin sztucznej inteligencji odnosi się do niezwykle dużych zbiorów danych, które są tak złożone i obszerne, że tradycyjne narzędzia do przetwarzania danych są nieodpowiednie do zarządzania nimi i ich analizowania.
Znaczenie Big Data polega nie tylko na rozmiarze danych, ale także na ich złożoności i szybkości, z jaką są generowane i przetwarzane. Tradycyjnie charakteryzuje się je tak zwanymi trzema V – Volume (objętość), Velocity (szybkość) i Variety (różnorodność):
- Objętość – odnosi się do samego rozmiaru danych zebranych z różnych źródeł, takich jak transakcje, media społecznościowe, sensory etc. Wzrost ilości danych został ułatwiony dzięki dostępności tańszych opcji przechowywania, takich jak jeziora danych (ang. data lakes), Hadoop i przechowywanie w chmurze.
- Szybkość – ten aspekt Big Data dotyczy szybkości, z jaką dane są generowane i muszą być przetwarzane.
- Różnorodność – Big Data występuje w różnych formatach – od ustrukturyzowanych, numerycznych danych w tradycyjnych bazach danych, po nieustrukturyzowany tekst, wideo, audio i inne.

Chatbot
Jest to aplikacja zaprojektowana do prowadzenia rozmów online za pomocą tekstu lub zamiany tekstu na mowę, symulująca interakcję międzyludzką. Pierwszym godnym uwagi przykładem była “Eliza”, stworzona w 1966 roku przez Josepha Weizenbauma. Eliza działała poprzez analizowanie wzorców zdań wprowadzanych przez użytkownika i stosowanie zastępowania słów kluczowych i zmiany kolejności słów w celu tworzenia odpowiedzi, tworząc iluzję zrozumienia. Jej skrypt "DOCTOR", naśladujący psychoterapeutę Rogeriana, był szczególnie znany z angażowania użytkowników w pozornie znaczące rozmowy.
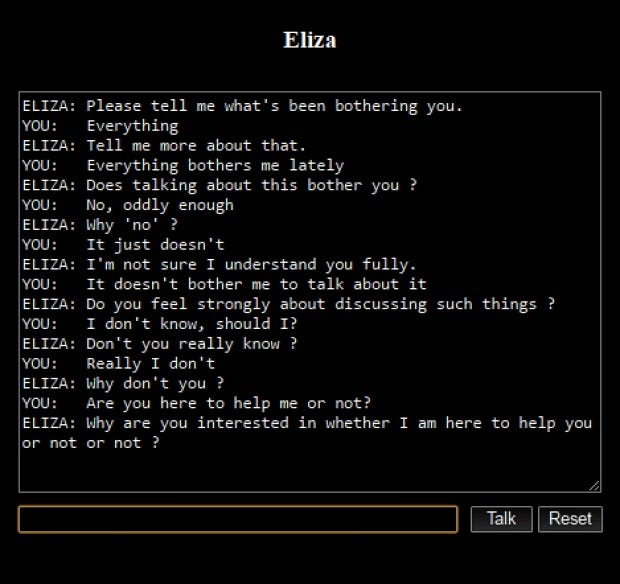
Źródło: medium.com
Dziedzina chatbotów znacznie ewoluowała od tych wczesnych przykładów. Nowoczesne chatboty, takie jak ChatGPT i Google Bard, wykorzystują zaawansowane technologie sztucznej inteligencji i uczenia maszynowego. Te współczesne wersje wyróżniają się zrozumieniem kontekstu, zarządzaniem złożonymi dialogami i dostarczaniem spójnych odpowiedzi, znacznie przewyższając możliwości swoich poprzedników.
Model dyfuzyjny (Diffusion model)
Model dyfuzyjny to klasa modeli generatywnych. Zwykle składają się one z trzech głównych komponentów: próbkowania, procesu postępującego i procesu odwrotnego. We współczesnym kontekście termin ten zwykle odnosi się do procesu generowania obrazu.
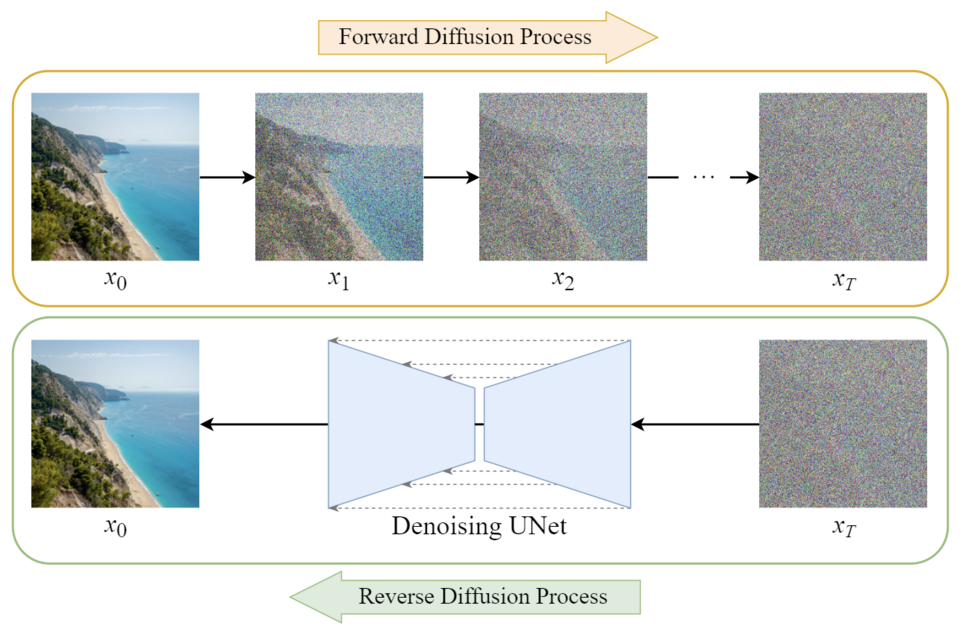
Źródło: towardsai.net
W dziedzinie generowania obrazów modele dyfuzyjne są trenowane na zestawach obrazów z dodanym sztucznym szumem. Zadaniem modelu jest iteracyjne usuwanie tego szumu, przy jednoczesnym skutecznym “uczeniu się” odtwarzania oryginalnego obrazu.
Proces ten umożliwia modelowi generowanie nowych obrazów na podstawie kombinacji danych wprowadzonych przez użytkownika i próbki ukrytego szumu. Działanie modeli dyfuzyjnych można potocznie podsumować wyrażeniem “widzę buzię w tej tęczy”, które metaforycznie ilustruje, w jaki sposób modele te rozpoznają ustrukturyzowane obrazy z pozornie losowych wzorców szumu.
Przykład modelu dyfuzyjnego w akcji, wygenerowany w Midjourney
Fine-tuning
Ten termin odnosi się do procesu modyfikowania już wyszkolonego modelu AI w celu dostosowania go do nowego, określonego zestawu danych lub zadania. Obejmuje on “dodawanie nowej wiedzy” do modelu. Na przykład, jeśli chcesz dostosować model OpenAI, aby odpowiadał na pytania oparte na danych z Twojej strony internetowej, dostroisz istniejący model za pomocą zestawu informacji pochodzących z witryny.
Fine-tuning może być czasochłonny w przypadku większych modeli i często wymaga dodatkowych mechanizmów w celu uwzględnienia zmian w danych. Na przykład opublikowanie nowego wpisu na blogu strony może wymagać ponownego przeszkolenia modelu w celu uwzględnienia tych nowych informacji. Dostrajanie pozwala dostosować modele sztucznej inteligencji do określonych domen lub wymagań bez konieczności trenowania ich od podstaw.
Generatywna sztuczna inteligencja (Generative AI)
Termin generatywna sztuczna inteligencja odnosi się do podzbioru modeli sztucznej inteligencji. Są one zaprojektowane do generowania nowych treści, opierając się na wzorcach i wiedzy wyciągniętej z danych szkoleniowych i danych wejściowych użytkownika. Takie modele są zdolne do wykonywania kreatywnych zadań, takich jak pisanie nowych utworów z zachowaniem stylu określonych autorów lub tworzenie sztuki i muzyki, które naśladują określone gatunki.
Na przykład model wyszkolony w dziełach Szekspira byłby w stanie generować nowe wiersze lub fragmenty tekstu, które naśladują jego unikalny styl i niuanse językowe. Kluczowym aspektem generatywnej sztucznej inteligencji jest jej zdolność do tworzenia oryginalnych wyników, które są spójne i kontekstowo istotne, a do tego często wyglądające tak, jakby stworzył je człowiek.
Rozmowa z ChatGPT
Duży model językowy (Large Language Model)
Termin ten opisuje klasę modeli sztucznej inteligencji, które są szkolone na ogromnych ilościach danych w języku naturalnym. Ich podstawową funkcją jest rozumienie, przetwarzanie i generowanie tekstu podobnego do ludzkiego. Modele LLM (ang. Large Language Model) osiągają to poprzez uczenie się na podstawie szerokiego spektrum danych językowych oraz wykorzystywanie prawdopodobieństwa statystycznego do odtwarzania i tworzenia nowych treści.
Modele te są nie tylko biegłe w generowaniu tekstu, który jest spójny i odpowiedni kontekstowo. Są także zdolne do wykonywania różnych zadań związanych z językiem, takich jak tłumaczenie, podsumowywanie i odpowiadanie na pytania. Rozmiar i różnorodność danych treningowych umożliwiają tym modelom szerokie “zrozumienie” języka, kontekstu i niuansów.
Przetwarzanie języka naturalnego (Natural Language Processing)
NLP (ang. Natural Language Processing) to dziedzina na styku informatyki, sztucznej inteligencji i lingwistyki. Koncentruje się na umożliwieniu komputerom rozumienia, interpretowania i generowania ludzkiego języka w wartościowy i znaczący sposób. Kluczowe zadania w NLP obejmują tłumaczenie języka, analizę nastrojów, rozpoznawanie mowy i podsumowywanie tekstu.
Celem jest stworzenie systemów, które mogą wchodzić w interakcje z ludźmi za pomocą języka, wydobywając spostrzeżenia z danych tekstowych lub mowy, a także generując odpowiedzi podobne do ludzkich. NLP łączy techniki obliczeniowe z wiedzą specyficzną dla języka, aby skutecznie przetwarzać i analizować duże ilości danych w języku naturalnym.
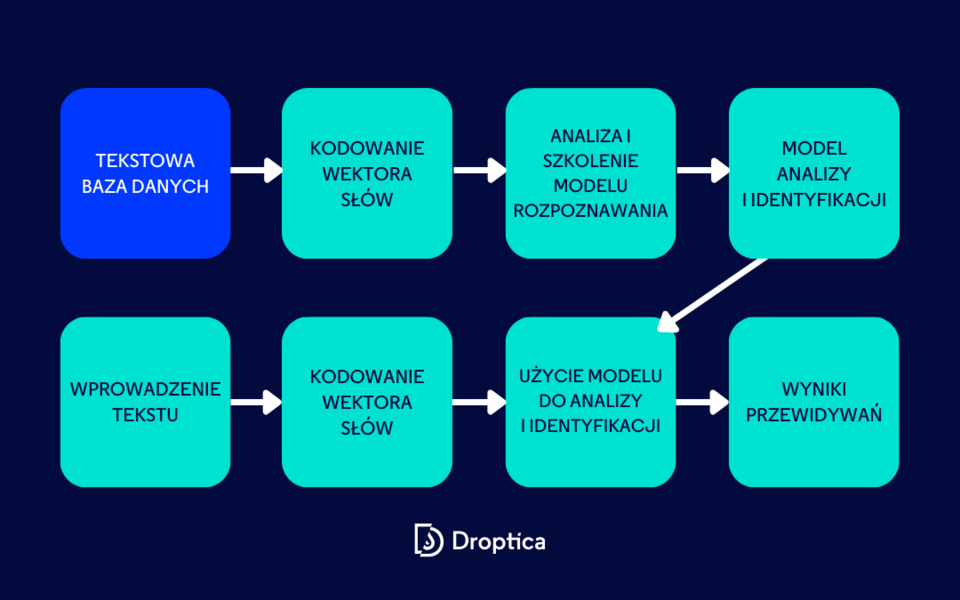
Optyczne rozpoznawanie znaków (Optical Character Recognition)
OCR (ang. Optical Character Recognition) to proces konwertowania obrazów tekstu odręcznego lub drukowanego na tekst kodowany maszynowo. Powszechnie stosowana jako forma wprowadzania danych, jest to powszechna metoda wykorzystywana do digitalizacji drukowanego tekstu, dzięki czemu można go przechowywać, edytować, przeszukiwać lub przekazywać do dużego modelu językowego (LLM).
Prompt
W kontekście sztucznej inteligencji prompt to dane wejściowe dostarczone przez użytkownika, które kierują modelem sztucznej inteligencji do wygenerowania określonego wyniku. Działa jako przewodnik lub instrukcja dla sztucznej inteligencji, kształtując jej odpowiedzi lub generowaną przez nią treść. Prompty mogą się znacznie różnić – od prostych pytań, po złożone scenariusze – i mają zasadnicze znaczenie dla określenia, w jaki sposób model sztucznej inteligencji interpretuje żądania użytkownika i reaguje na nie.
Inżynieria podpowiedzi (Prompt Engineering)
Ta rozwijająca się dziedzina koncentruje się na optymalizacji interakcji z modelami sztucznej inteligencji w celu osiągnięcia pożądanych wyników. Inżynieria podpowiedzi (ang. Prompt Engineering) obejmuje dogłębne zrozumienie sposobu, w jaki modele sztucznej inteligencji przetwarzają język naturalny i opracowują prompty, aby poprowadzić sztuczną inteligencję w kierunku określonych rozwiązań lub odpowiedzi.
Jest to szczególnie istotne w kontekście dużych modeli językowych, w których sposób sformułowania promptu może znacząco wpłynąć na wynik modelu. Dziedzina ta zyskuje na znaczeniu, ponieważ systemy sztucznej inteligencji stają się coraz bardziej powszechne i wyrafinowane, co wymaga umiejętnych technik, aby skutecznie wykorzystać ich możliwości.
Token
W dziedzinie LLM token jest podstawową jednostką tekstu przetwarzaną przez model. Pojęcie tokena wynika z procesu “tokenizacji”, w którym tekst wejściowy jest dzielony na mniejsze części lub tokeny. Tokeny te są następnie wykorzystywane przez model do rozumienia i generowania tekstu. Należy zauważyć, że token niekoniecznie odpowiada pojedynczemu znakowi. Na przykład w języku angielskim token może reprezentować słowo lub część słowa, zazwyczaj o średniej długości około czterech znaków.
Dokładna definicja tokena może się różnić w zależności od modelu językowego i specyfiki jego algorytmu tokenizacji. Tokeny mają kluczowe znaczenie dla modeli przetwarzania danych wejściowych w języku naturalnym i generowania spójnych odpowiedzi lub tekstu, ponieważ określają ziarnistość, z jaką model interpretuje dane wejściowe.
Podstawowe pojęcia AI – podsumowanie
W tym artykule ukazaliśmy znaczenie terminów i pojęć związanych ze sztuczną inteligencją i mamy nadzieję, że rozwialiśmy niektóre wątpliwości i niejasności. Zrozumienie tych podstawowych zwrotów jest niezbędne dla każdego, kto chce zaangażować się w rozwijającą się dziedzinę sztucznej inteligencji – czy to w celu rozwoju kariery, czy z osobistej ciekawości. Jeśli chciałbyś przekuć którykolwiek z tych obszarów w konkretny projekt, możesz skorzystać z pomocy naszych specjalistów doświadczonych w usługach AI development.










